-
네이버 금융에서 ETF 기초 정보 갈무리(크롤링)하는 법Python/파이썬과 주식, 코인 2020. 11. 1. 19:12반응형
퀀트를 하는 건 아니지만..
ETF 포트폴리오를 여러가지로 백테스트하다보니까..
ETF 수수료가 궁금해졌습니다.
453개의 ETF 하나하나 조사하기는 힘듭니다.
파이썬의 힘을 좀 빌려야겠네요.먼저 저도 가물가물해진 ETF 목록 크롤링하는 법을 보고 옵니다.
comdoc.tistory.com/entry/네이버-주식을-이용해-ETF-목록-갈무리하는-법다음으론 목표를 확인합니다.
finance.naver.com/item/main.nhn?code=069500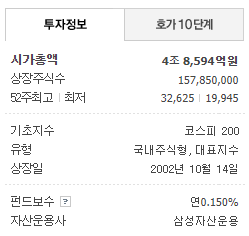

이제 열심히 코딩합니다.
import csv import json import urllib.request from bs4 import BeautifulSoup url = 'https://finance.naver.com/api/sise/etfItemList.nhn' raw_data = urllib.request.urlopen(url).read().decode('CP949') json_data = json.loads(raw_data) f = open('output.csv', 'w', encoding='utf-8', newline='') wr = csv.writer(f) for each in json_data['result']['etfItemList']: url = 'https://finance.naver.com/item/main.nhn?code=' + each['itemcode'] raw_data = urllib.request.urlopen(url).read().decode('CP949') soup = BeautifulSoup(raw_data) info1 = soup.body.find('table', summary="시가총액 정보").find_all('em') info2 = soup.body.find('table', summary="기초지수 정보").find_all('td') info3 = soup.body.find('table', summary="펀드보수 정보").find_all('td') info_all = [ each['itemname'], each['itemcode'], info1[0].get_text(strip=True).replace('\t', '').replace('\n', '') + '억원', info1[1].get_text(), info2[0].get_text(), info2[1].get_text(), info2[2].get_text(), info3[0].get_text(), info3[1].get_text() ] print(info_all) wr.writerow(info_all) f.close()저는 구글의 스프레드시트와 CSV 포맷을 즐겨씁니다.
엑셀을 별로 안 좋아해서..결과 CSV를 첨부합니다.
국내 453개의 ETF 이름, 코드, 시가총액, 상장주식수, 기초지수, 유형, 상장일, 펀드보수, 운용사를 정리했습니다.구글 스프레드시트에서 열어보면 잘 보일 겁니다.

CSV 파일은 텍스트 에디터로 읽을 수도 있습니다.
만약 엑셀로 보고 싶으시다면,
텍스트 에디터를 이용해서 유니코드(UTF-8)를 ANSI(또는 EUC-KR, CP949)로 변환 후 저장하면 됩니다.저는 notepad++를 사용합니다.
반응형